
Last updated on 07th Aug 2025| 12295
- What is Transfer Learning?
- Types of Transfer Learning
- Pre-trained Models
- Fine-Tuning vs Feature Extraction
- Popular Architectures (ResNet, BERT, etc.)
- Transfer Learning in NLP
- Transfer Learning in Computer Vision
- Domain Adaptation
- Cross lingual Transfer Learning
- Advantages and Challenges
- Case Studies and Applications
- Conclusion
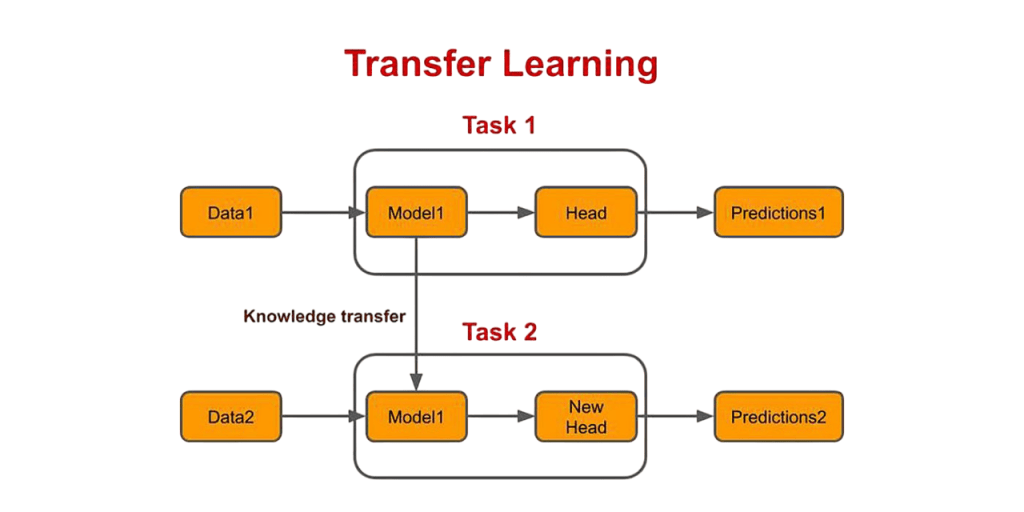
What is Transfer Learning?
Transfer learning is a Machine Learning Training technique where knowledge gained from solving one problem is used to solve a different but related problem. Instead of training a model from scratch, a pre-trained model trained on a large dataset is reused and adapted for a new task. This approach saves computational resources, accelerates training, and often leads to better performance, especially when the new task has limited data. In transfer learning, a model trained on a source domain is repurposed on a target domain. The key insight is that early layers of deep neural networks capture generic features (e.g., edges or shapes in images) which are transferable across similar tasks.
Ready to Get Certified in Machine Learning? Explore the Program Now Machine Learning Online Training Offered By ACTE Right Now!
Types of Transfer Learning
Transfer learning has three main types: inductive, transductive, and unsupervised. In inductive transfer learning, the source and target tasks are different. The source domain has a lot of labeled data, while the target domain has little or no labeled data. This method is often used in classification tasks. Pattern Recognition and Machine Learning provides foundational techniques for such problems. Transductive transfer learning, on the other hand, involves the same task in different domains. For example, a sentiment analysis model trained on English text can be adjusted to work with Spanish text. Finally, unsupervised transfer learning is used when both the source and target data are unlabeled. It is especially helpful for tasks like clustering and reducing dimensions.
Pre-trained Models
Pre-trained models are those trained on large benchmark datasets such as ImageNet (for vision) or Wikipedia (for NLP). These models encapsulate useful feature representations which are then reused for other tasks.
Examples:
- ImageNet-trained models like VGG, ResNet, MobileNet
- NLP models like BERT, GPT, RoBERTa, T5
Using pre-trained models eliminates the need for extensive computation and training time. It also results in models that generalize well to new datasets.
To Explore Machine Learning in Depth, Check Out Our Comprehensive Machine Learning Online Training To Gain Insights From Our Experts!
Types of Transfer Learning
There are two primary approaches in transfer learning: Overview of ML on AWS often highlights how these approaches can be implemented efficiently using scalable cloud infrastructure and pre-trained models.
Feature Extraction:
- Freeze the convolutional base of the pre-trained model.
- Replace the top layers (classifier or decoder) with new layers suited for the target task.
- Train only the new layers.
Fine-Tuning:
- Unfreeze some or all of the layers of the pre-trained model.
- Continue training the entire model on the target dataset.
- This allows the model to adapt better to the specific characteristics of the target domain.
The choice depends on the size of the new dataset and the similarity between the source and target domains.

Popular Architectures (ResNet, BERT, etc.)
ResNet (Residual Network) is commonly used in computer vision tasks. It tackles the vanishing gradient problem in deep convolutional neural networks by introducing residual blocks. These blocks help layers learn identity mappings more easily. In contrast, VGG has a simpler and more uniform architecture. In the context of Machine Learning Training, it acts as a strong baseline model for image classification tasks. In natural language processing, BERT (Bidirectional Encoder Representations from Transformers) changed how models understand language by using context from both directions.
BERT gets trained with masked language modeling and next sentence prediction tasks. Meanwhile, GPT (Generative Pre-trained Transformer) uses a unidirectional transformer to predict the next word in a sequence. It is pretrained on large text collections and excels in text generation, translation, and summarization tasks.
Transfer Learning in NLP
Transfer learning in NLP usually involves using large language models that are trained on general text and then adjusted for specific tasks. Common uses include sentiment analysis, named entity recognition (NER), machine translation, and question answering. Popular models for transfer learning are BERT, RoBERTa, and DistilBERT, which work well for tasks like embeddings and classification. For text generation tasks, models such as GPT, T5, and BART are commonly used. Understanding the Machine Learning Engineer Salary helps professionals align their skill development with market demand and compensation trends. One of the main advantages of transfer learning in NLP is that it leads to better results with less labeled data. Models can also be adjusted for specific needs, as seen in versions like BioBERT for biomedical texts and FinBERT for financial data.
Looking to Master Machine Learning? Discover the Machine Learning Expert Masters Program Training Course Available at ACTE Now!
Transfer Learning in Computer Vision
Computer vision was one of the first fields to widely adopt transfer learning. The general approach includes:
- Using a CNN like ResNet, MobileNet, or Inception pre-trained on ImageNet.
- Removing the top layer.
- Adding a new dense layer for classification.
- Freezing or unfreezing layers based on the task.
Tasks include:
- Image classification
- Object detection
- Face recognition
- Image segmentation
Transfer learning has significantly reduced the need for large labeled datasets in vision tasks.
Domain Adaptation
Domain adaptation is a form of transfer learning where the task remains the same, but the domain changes. The challenge is to bridge the distribution gap between source and target domains. Machine Learning Tools are essential in addressing this challenge, offering techniques and frameworks to align feature spaces and improve cross-domain performance.
Techniques:
- Domain adversarial training
- Feature space alignment
- Instance re-weighting
Example:
A speech recognition system trained on English voices being adapted to recognize regional accents or other languages.
Preparing for Machine Learning Job Interviews? Have a Look at Our Blog on Machine Learning Interview Questions and Answers To Ace Your Interview!
Cross lingual Transfer Learning
Cross lingual Transfer Learning involves using models trained in one language for tasks in other languages. This method is particularly useful for low-resource languages, where labeled data is limited. Machine Learning Algorithms help overcome data scarcity by leveraging transfer learning, pre-trained models, and efficient training strategies. Common techniques include using multilingual pre-trained models like mBERT and XLM-R, translating datasets from high-resource languages to low-resource languages, and aligning word embeddings between languages. The main benefits of Cross lingual Transfer Learning are the reduced need for labeled data in various languages and improved global access to AI applications.
Advantages and Challenges
Advantages:
- Efficiency: Saves time and computational resources.
- Performance: Often leads to better results with less data.
- Flexibility: Applicable to various domains like vision, NLP, and audio.
- Accessibility: Lowers the barrier for smaller teams or companies.
Challenges:
- Overfitting: Especially if the source and target domains differ significantly.
- Negative transfer: When knowledge from the source task degrades performance on the target task.
- Model size: Pre-trained models can be computationally heavy.
Case Studies and Applications
- Using ImageNet-pretrained models for X-ray or MRI classification.
- Reduces need for expert-labeled medical data.
Chatbots and Virtual Assistants:
- Fine-tuning BERT or GPT models for customer service, HR, or legal support.
- Using FinBERT to analyze sentiment in financial news and reports.
- Plant disease detection using pre-trained CNN models adapted for agricultural datasets.
- Transfer of visual recognition models from simulation to real-world driving environments.
Conclusion
As artificial intelligence models grow larger, this approach becomes even more important. Datasets are also becoming more diverse. They cover a wider range of information. In this expanding world of AI, the value of Machine Learning Training through transfer learning keeps increasing. For example, in natural language processing, a model trained on general text can quickly learn to understand medical reports. In computer vision, a model that recognizes everyday objects can be adjusted to spot tiny defects in industrial parts. This ability to reuse and modify existing models is essential. Transfer learning eliminates this issue. It opens up AI development to more people and allows them to create powerful AI solutions. It drives progress in understanding human speech, innovation in analyzing medical images for disease detection, and smarter automation in factories. The future of accessible and effective AI depends heavily on this smart transfer of knowledge.

